
The Best Articles in Data Science
The most useful articles in Data Science from around the web, curated by thought leaders and our community.
Refind focuses on timeless pieces and updates the list whenever new, must-read articles or videos are discovered.
Top 5 Data Science Articles
At a glance: these are the articles that have been most read, shared, and saved in Data Science by Refind users in 2024 so far.
What is ...?
New to Data Science? These articles make an excellent introduction.
What is Reverse ETL? The Definitive Guide
Learn everything there is to know about Reverse ETL, how it fits into the modern data stack, and why it's different than ETL.

Learn Julia For Beginners – The Future Programming Language of Data Science and Machine Learning Explained
Julia is a high-level, dynamic programming language, designed to give users the speed of C/C++ while remaining as easy to use as Python. This means that developers can solve problems faster and more…
«So now the function is defined to take in only a string. Let us test this out to make sure we can only call the function with a string value»

An introduction to data science and machine learning with Microsoft Excel
Microsoft Excel is a powerful tool for learning the basics of data science and machine learning.
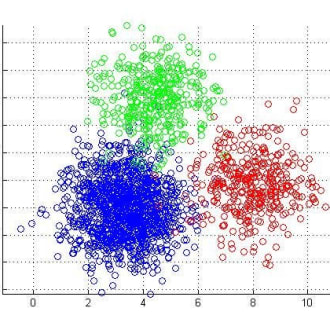
What is Hierarchical Clustering?
By Nagesh Singh Chauhan, Big data developer at CirrusLabs What is Clustering?? Clustering is a technique that groups similar objects such that the objects in the same group are more similar to each…
Trending
These links are currently making the rounds in Data Science on Refind.

Analysis | Wait, does America suddenly have a record number of bees?
A gold-standard source shows a stunning boom in U.S. honeybee populations. Could that possibly be right? A Department of Data analysis found two possible explanations, one more surprising than the other.

A long read about NBA shot data
I used to play basketball and I do a lot of data analysis and mapping, but I haven't actually blogged about it before, so here I am. Scroll ...
Short Articles
Short on time? Check out these useful short articles in Data Science—all under 10 minutes.

The Myth of Objective Data
When we view objectivity and subjectivity as opposites rather than complements, we distort the empirical realities of data collection.
«This despair helps my students recognize an apparently banal assignment as a real design situation. It teaches them that data is created, not found; and that creating it well demands humanity, rather than objectivity.»

Researchers Warn We Could Run Out of Data to Train AI by 2026. What Then?
AI trained on ever-more data has yielded ChatGPT and DALL-E 3. But research shows online data stocks are growing more slowly than datasets used to train AI.
«Another option is to use AI to create synthetic data to train systems. In other words, developers can simply generate the data they need, curated to suit their particular AI model.»

The limits of our personal experience and the value of statistics
The world is huge; to get a clear idea of what our world is like, we have to rely on carefully collected, well documented statistics.

Explaining base rate neglect
In a seminar for a team from an investment manager I described how base rates are often neglected when people are grappling with conditional probabilities.

How Do They Know This?
An informative and apolitical new book reminds us that statistics are not always what they seem.
«But for the most part, official statistics are imperfect but good enough.»
Long Articles
These are some of the most-read long-form articles in Data Science.

Spinning Data into Thought
How Computers Think: Introduction

Dashboards Are Dead: 3 Years Later
What’s the purpose of dashboards in 2023?

Are You Ready to Hire a Data Scientist? Advice for Founders
Are you ready to hire a data scientist? Mengying Li, Growth Data Science Lead at Notion, shares her framework for testing whether you should invest in this key hire and how to find the right data…

A search engine in 80 lines of Python
February 05, 2024 · 26 mins · 4728 words Discussion on HackerNews. Last September I hopped on board with Wallapop as a Search Data Scientist and since then part of my work has been working with Solr,…

Megastudy scepticism
In December last year Katherine Milkman and friends published a “megastudy” testing 54 interventions to increase the gym visits of 61,000 experimental participants.
Thought Leaders
We monitor hundreds of thought leaders, influencers, and newsletters in Data Science, including:
What is Refind?
Every day Refind picks the most relevant links from around the web for you. Picking only a handful of links means focusing on what’s relevant and useful.
How does Refind curate?
It’s a mix of human and algorithmic curation, following a number of steps:
- We monitor 10k+ sources and 1k+ thought leaders on hundreds of topics—publications, blogs, news sites, newsletters, Substack, Medium, Twitter, etc.
- In addition, our users save links from around the web using our Save buttons and our extensions.
- Our algorithm processes 100k+ new links every day and uses external signals to find the most relevant ones, focusing on timeless pieces.
- Our community of active users gets the most relevant links every day, tailored to their interests. They provide feedback via implicit and explicit signals: open, read, listen, share, mark as read, read later, «More/less like this», etc.
- Our algorithm uses these internal signals to refine the selection.
- In addition, we have expert curators who manually curate niche topics.
The result: lists of the best and most useful articles on hundreds of topics.
How does Refind detect «timeless» pieces?
We focus on pieces with long shelf-lives—not news. We determine «timelessness» via a number of metrics, for example, the consumption pattern of links over time.
How many sources does Refind monitor?
We monitor 10k+ content sources on hundreds of topics—publications, blogs, news sites, newsletters, Substack, Medium, Twitter, etc.
Who are the thought leaders in Data Science?
We follow dozens of thought leaders in Data Science, including Andrew Ng, Hilary Mason, Werner Vogels, Nathan Yau, Data Science Renee.
Missing a thought leader? Submit them here
Can I submit a link?
Indirectly, by using Refind and saving links from outside (e.g., via our extensions).
How can I report a problem?
When you’re logged-in, you can flag any link via the «More» (...) menu. You can also report problems via email to hello@refind.com
Who uses Refind?
450k+ smart people start their day with Refind. To learn something new. To get inspired. To move forward. Our apps have a 4.9/5 rating.
Is Refind free?
Yes, it’s free!
How can I sign up?
Head over to our homepage and sign up by email or with your Twitter or Google account.
Keep Learning
Learn something new, guided by experts. Deep Dives are carefully hand-curated series of time-tested articles and videos from around the web.
Get the big picture on your favorite topics.